Remember, we love OTV because it has the ability to connect Data Centers and make it appear as if they are connected Layer 2 domains. While there are other technologies that can do this, OTV is appealing for many reasons including its flexibility and simplicity of configuration and operation.
In order to understand the further study of OTV, you really need to be able to speak its language, and that means learning some terms that are commonly used to describe it. Here they are:
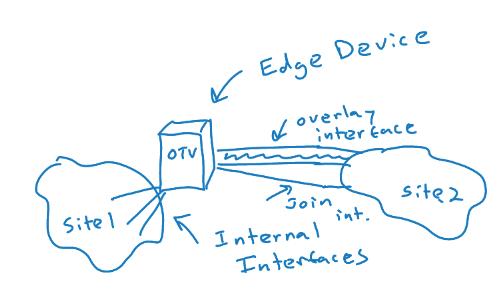
- OTV Edge Device – this device takes the Layer 2 frames and encapsulates them in Layer 3 packets; in a “classic” implementation, the OTV device is a VDC of a Nexus 7K
- OTV Internal Interface – a layer 2 interface on an edge device that connects to the VLANs that are to be encapsulated
- OTV Join Interface – a Layer 3 interface that is used to join the two domains and discover the remote OTV device
- Transport Network – the network connecting the OTV sites
- Overlay Network – the logical network that connects the two OTV devices
- Site VLAN – a VLAN that carries hellos between edge devices that might exist at the same site; it is best to use a dedicated VLAN for this role; this VLAN is not extended across the overlay
- AED – the Authoritative Edge Device is elected for a site and is the designated forwarding edge device; devices maintain adjacency with each edge device in a site (site adjacency); they use the Site VLAN for this purpose; they also maintain the overlay adjacency using the join interface to a remote site