Overview
This post covers content from my upcoming AWS Solutions Architect – Storage course at CBT Nuggets.
One of the many purposes for your AWS S3 bucket is to host a static web site. Keep in mind that your site can still feature client-side scripts. It is just unable to support server-side scripts like PHP, JSP, or ASP.NET. Obviously, for such a dynamic site, there are other alternatives in AWS for hosting. Amazon Lightsail, for example, provides an easy way to launch and manage a Web server using AWS. Lightsail includes everything you need to jumpstart your Website – a virtual machine, SSD-based storage, data transfer, DNS management, and a static IP – for a low, predictable price.
Your Site
Hosting your site with S3 is simple. You create your bucket, upload your files, and then you have a specific site endpoint at:
<bucket-name>.s3-website-<AWS-region>.amazonaws.com
The URL that would return your default home page (index document) would be:
http://examplebucket.s3-website-us-west-2.amazonaws.com/
Of course you would want to use your own domain, such as example.com to serve your content. Amazon S3, along with Amazon Route 53, supports hosting a website at the root domain.
Required Configurations
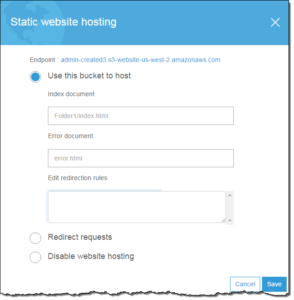
Enabling Website Hosting
Follow these steps to enable website hosting for your Amazon S3 buckets using the Amazon S3 console:
- Sign in to the AWS Management Console and open the Amazon S3 console.
- In the list, choose the bucket that you want to use for your hosted website.
- Choose the Properties tab.
- Choose Static website hosting, and then choose Use this bucket to host a website.
- You are prompted to provide the index document and any optional error documents and redirection rules that are needed.
Configuring Index Document Support
An index document is a webpage that Amazon S3 returns when a request is made to the root of a website or any subfolder. For example, if a user enters http://www.example.com in the browser, the user is not requesting any specific page. In that case, Amazon S3 serves up the index document, which is sometimes referred to as the default page.
When you configure your bucket as a website, provide the name of the index document. You then upload an object with this name and configure it to be publicly readable.
In Amazon S3, a bucket is a flat container of objects; it does not provide any hierarchical organization as the file system on your computer does. You can create a logical hierarchy by using object key names that imply a folder structure. For example, consider a bucket with three objects and the following key names.
pic1.jpgphotos/2016/Jan/pic2.jpgphotos/2016/Feb/pic3.jpg
Although these are stored with no physical hierarchical organization, you can infer the following logical folder structure from the key names.
pic1.jpgobject is at the root of the bucket.pic2.jpgobject is in thephotos/2016/Jansubfolder.pic3.jpgobject is in thephotos/2016/Febsubfolder.
Permissions
When you configure a bucket as a website, you must make the objects that you want to serve publicly readable. To do this, you write a bucket policy that grants everyone s3:GetObject permission. On the website endpoint, if a user requests an object that doesn’t exist, Amazon S3 returns HTTP response code 404 (Not Found). If the object exists but you haven’t granted read permission on it, the website endpoint returns HTTP response code 403 (Access Denied). The user can use the response code to infer whether a specific object exists. If you don’t want this behavior, you should not enable website support for your bucket.
Of course there are several optional configurations permitted, but that is for another post!