Many things have changed in the data center over the last decade or so. In fact, so much has changed that the “old” three-layer model of access, aggregation, and core is no longer ideal. This model focused on a “south to north” flow of data. Thanks to virtualization technologies of data, there is much more of an “east to west” flow of data between virtualized workloads in an expanded layer 2 domain.
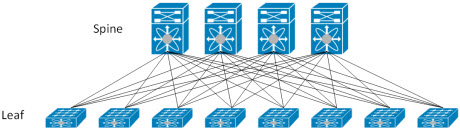
In this new two tier architecture, every leaf layer switch connects to each of the spine switches in a full mesh topology. Of course, the leaf devices connect directly to your servers (hosting God knows how many containers and VMs) and the spine layer forms the high speed core of your network. With each leaf switch connecting to every spine device, traffic is randomly load balanced across the multiple paths that exist, and a failure of a spine device has a very minimal disruption on the overall data center.
Oversubscription issues are handled with ease. New leaf switches are added when ports are in short supply for your servers, and new spine devices can be added when overall bandwidth begins to suffer.
Notice also that this design provides much more predictable latency. This is because server to server communication always involves the same number of devices in the path (unless you get lucky and the servers are connected to the same leaf device).
Spine and leaf topologies lend themselves beautifully to overlay technologies in order to solve many data center challenges. Specific Cisco overlay, spine and leaf architectures include:
- Cisco FabricPath Spine and Leaf
- Cisco VXLAN Flood-and-Learn Spine and Leaf
- Cisco VXLAN MP-BGP Ethernet VPN Spine and Leaf
- Cisco Massively Scalable Data Center (MSDC) Layer 3 Spine and Leaf
I hope this has been informative for you, and I would like to thank you for reading!
Thanks Anthony for this post.
Does Spine switches connect to each other directly? Is there any HSRP or VRRP between the Spine switches?
The spine devices might be connected to each other depending on your choice of overlay technologies. For example, you might connect them and use VPC+. HSRP and VRRP are supported technologies for gateway redundancy. Many of these options are discussed in this excellent post – http://lostintransit.se/2015/05/28/design-considerations-for-northsouth-flows-in-the-data-center/